自己写了博客,一般总是希望被更多的人看到,而他人找到你的网站的最好方法就是通过搜索引擎。所以为了能够让你的网站被收录在搜索引擎中,需要向搜索引擎主动提交 (当然,如果你是 dl,大可不必如此麻烦)
如果你是通过Hexo建立的网站,有很多的插件可以提供你使用,例如 hexo-submit-urls-to-search-engine ,配置可以看插件的文档 ,除了这种方法之外,还可以自己用Python写一个自动提交的程序。
流程 如果需要主动推送谷歌的话,需要会科学上网,再加上个人觉得没什么必要,所以只添加了前两个的 push
依赖 1 2 3 4 5 import re, os, urllib, requestsfrom urllib import requestfrom bs4 import BeautifulSoupimport xml.dom.minidomfrom xml.dom.minidom import parse
一般情况下,只要安装BeautifulSoup就好了
收录情况 在搜索引擎中输入site:example.com就可以查看你的网站的收录情况
百度 1 2 3 4 data = requests.get('http://www.baidu.com/s?wd=site:' +url) content = data.content.decode('utf-8' ) soup = BeautifulSoup(content,'lxml' ) link_list = soup.find_all('a' )
这部分实现的是查询site:example.com,并且获取页面中所有的链接
1 2 3 4 5 site_list = [] for link in link_list : url = link.get('href' ) rul = re.compile (r'http://www.baidu.com/link\?url=+.+' ) url = rul.findall(url)
这部分是将无关的链接全部排除;百度的搜索结果都是以http://www.baidu.com/link/?url=进行替换的,而我们要获得的是真实网址,所以下一步要通过访问这个链接,获取真实指向的网址:
1 2 3 4 5 6 7 8 9 try : response = request.urlopen(url[0 ]) realurl = response.geturl() if realurl!='' : site_list.append(realurl) except request.HTTPError as e : print (e.code, e.reason) except urllib.error.URLError as e : data = requests.get(url[0 ])
urllib.error.URLError是为了防止有时候 DNS 解析不到某些域名的网址,导致程序直接退出
必应 必应和百度不同,搜索出来的结果直接就是页面链接,不需要获得真实网址:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 data = requests.get('https://cn.bing.com/search?q=site:{}&first={}0' .format (url, page)) content = data.content.decode('utf-8' ) soup = BeautifulSoup(content,'lxml' ) link_list = soup.find_all('a' ) site_list = [] for link in link_list : url = link.get('href' ) if url==None : continue rul = re.compile (r'https://www.foolishfox.cn/+.+' ) url = rul.findall(url) if url==None or not url : continue site_list.append(url[0 ]) return site_list
站点链接 可以通过很多手段获得站点地图。以我的网站为例,使用hexo-generator-sitemap直接获得了sitemap.xml文件
1 2 3 4 5 6 7 8 DOMTree = xml.dom.minidom.parse(path) sizemap = DOMTree.getElementsByTagName('loc' ) site_list = [] for i in range (0 , len (sizemap), 1 ): url = sizemap[i].firstChild.data if 'tags' not in url and 'categories' not in url : site_list.append(url) return site_list
百度提交 1 2 3 4 5 6 7 8 9 10 11 s_url = 'http://data.zz.baidu.com/urls?site=https://www.foolishfox.cn&token=' +os.environ['baidu_token' ] headers = { 'content-type' : 'text/plain' , 'User-Agent' : 'curl/7.12.1' , 'Host' : 'data.zz.baidu.com' } url_string = '' for link in url_list : url_string += link+'\n' response = requests.request('POST' , url=s_url, data=url_string, headers=headers) return response.text
百度 API 的 token 我已经提前设置在了环境变量中,可以避免对外公开。需要注意的是,百度 API 的格式要求是字符串 ,所以我将list拼接成了string。
必应提交 1 2 3 4 5 6 7 8 9 10 11 12 13 s_url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=' +os.environ['bing_token' ] headers = { 'content-type' : 'application/json' , 'User-Agent' : 'curl/7.12.1' } url_json = { 'siteUrl' : 'https://www.foolishfox.cn' , 'urlList' : [] } for link in url_list : url_json['url' ].append(link) response = requests.request('POST' , url=s_url, json=url_json, headers=headers) return response.text
必应可以采用xml和json两种格式提交,我用的是后者。如果提交单个链接,应该将s_url修改为https://ssl.bing.com/webmaster/api.svc/json/SubmitUrl?apikey=,将json中的urlList修改为url
自动提交 最简单的方式就是通过crontab了,如果使用Hexo,还可以用node.js监听hexo事件,实现提交:
1 2 3 4 5 6 7 try { hexo.on ('deployAfter' , function ( run (); }); } catch (e) { console .log ("Error: " + e.toString ()); }
更新 2020.12.19: 修改代码中链接、流程和部分单词拼写错误 参考资料 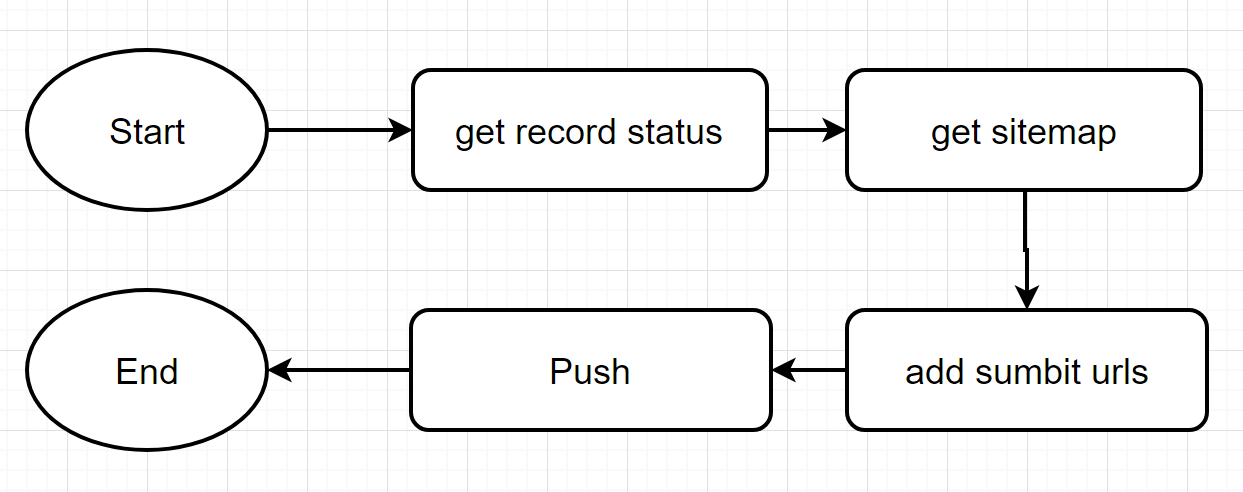
 wechat
wechat






